Optimizing the Hypre solver for manycore and GPU architectures
D. Sahasrabudhe, R. Zambre, A. Chandramowlishwaran, M. Berzins.
In Journal of Computational Science, Springer International Publishing, pp. 101279. 2020. DOI: https://doi.org/10.1016/j.jocs.2020.101279
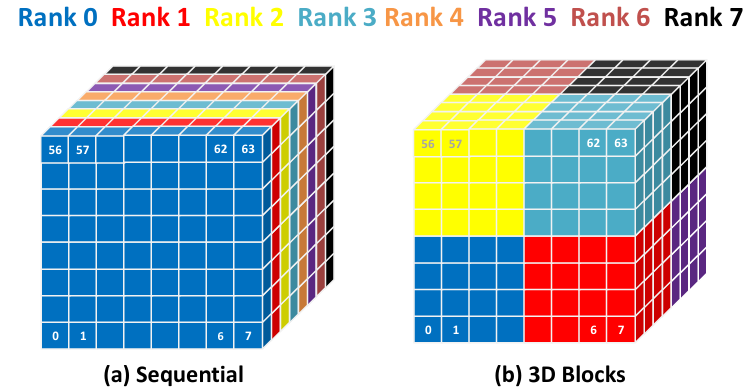
Figure 1: Communication reducing patch assignment: Simple sequential patch to rank assignment results into 2304 MPI messages, while cubicle assignment results into only 864 messages.
Abstract
The solution of large-scale combustion problems with codes such as Uintah on modern computer architectures requires the use of multithreading and GPUs to achieve performance. Uintah uses a low-Mach number approximation that requires iteratively solving a large system of linear equations. The Hypre iterative solver has solved such systems in a scalable way for Uintah, but the use of OpenMP with Hypre leads to at least 2× slowdown due to OpenMP overheads. The proposed solution uses the MPI Endpoints within Hypre, where each team of threads acts as a different MPI rank. This approach minimizes OpenMP synchronization overhead and performs as fast or (up to 1.44×) faster than Hypre’s MPI-only version, and allows the rest of Uintah to be optimized using OpenMP. The profiling of the GPU version of Hypre shows the bottleneck to bethe launch overhead of thousands of micro-kernels. The GPU performance was improved by fusing these micro-kernels and was further optimized by using Cuda-aware MPI, resulting in an overall speedup of 1.16–1.44× compared to the baseline GPU implementation.The above optimization strategies were published in the International Conferenceon Computational Science 2020. This work extends the previously published research by carrying out the second phase of communication-centered optimizations in Hypre to improve its scalability on large-scale supercomputers. This includes an efficient non-blocking inter-thread communication scheme, communication-reducing patch assignment, and expression of logical communication parallelism to a new version of the MPICH library that utilizes the underlying network parallelism. The above optimizations avoid communication bottlenecks previously observed during strong scaling and improve performance by up to 2× on 256 nodes of Intel Knight’s Landings processor.
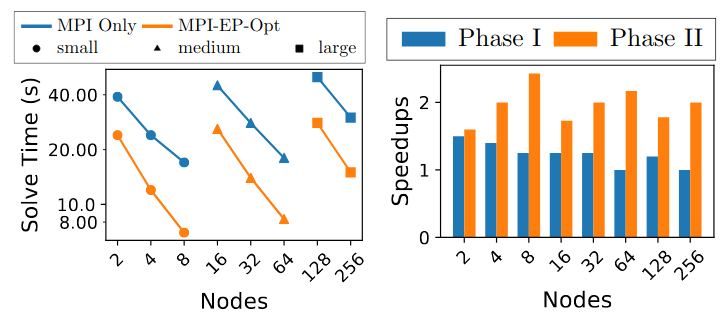
Figure 2: Up to 2.4x speedups du e new new improvements compared to the MPI only baseline version (on the left). speedups from ICCS 2020 paper compared to the latest improvements (on the right)