Improving Performance of the Hypre Iterative Solver for Uintah Combustion Codes on Manycore Architectures Using MPI Endpoints and Kernel Consolidation
D Sahasrabudhe, M. Berzins.
In Computational Science -- ICCS 2020, 20th International Conference, Amsterdam, The Netherlands, June 3–5, 2020, Proceedings, Part I, Springer International Publishing, pp. 175--190. 2020. ISBN: 978-3-030-50371-0 DOI: https://doi.org/10.1007/978-3-030-50371-0_13
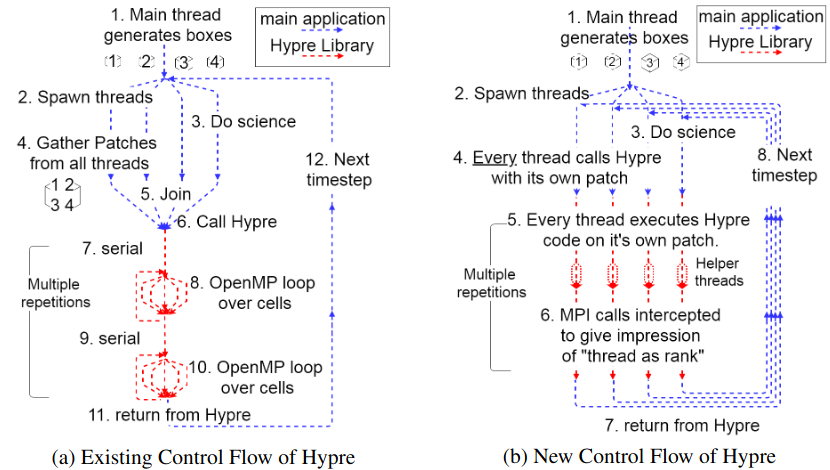
Figure 1: Using OpenMP across cell iterators requires thousands of OpenMP thread synchronizations as shown in Figure a. The synchronization overhead can not be justified for small loops. The alternate strategy of MPI EndPoint (MPI EP), where each thread (or a team of threads) acts as an MPI rank, is shown in Figure b.
Abstract
The solution of large-scale combustion problems with codes such as the Arches component of Uintah on next-generation computer architectures requires using a many and multi-core threaded approach and/or GPUs to achieve performance. Such codes often use a low-Mach number approximation that requires the iterative solution of a large system of linear equations at every time step. While the discretization routines in such a code can be improved by using, say, OpenMP or Cuda approaches, it is important that the linear solver be able to perform well too. For Uintah the Hypre iterative solver has proved to solve such systems in a scalable way. The use of Hypre with OpenMP leads to at least 2xslowdownsdue to OpenMP overheads, however. This behavior is analyzed, and a solution proposed by using the MPI Endpoints approach is implemented within Hypre, where each team of threads acts as a different MPI rank. This approach minimized OpenMP synchronization overhead, avoided slowdowns, performed as fast or (up to 1.5x) faster than Hypre’s MPI only version, and allowed the rest of Uintah to be optimized using OpenMP. Profiling of the GPU version of Hypreshowed the bottleneck to be the launch overhead of thousands of micro-kernels.The GPU performance was improved by fusing these micro kernels and was further optimized by using Cuda-aware MPI. The overall speedup of 1.26x to 1.44xwas observed compared to the baseline GPU implementation.
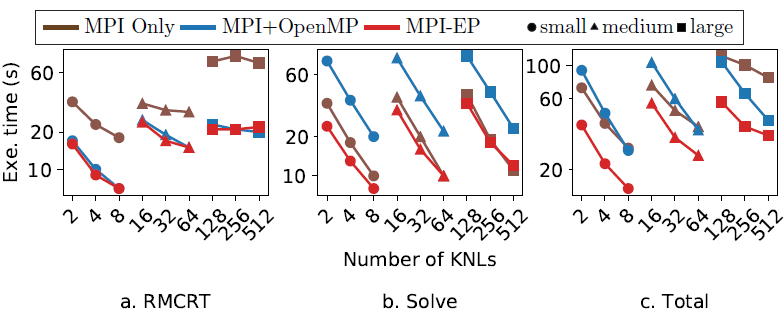
Figure 2: The effect of multithreading on Uintah's RMCRT component, Hypre Solver (this work) and overall simulation. The MPI EP avoids slowdowns observed in the default OpenMP version of the solver (Figure b) and improves overall simulation time (Figure c).