A Portable SIMD Primitive using Kokkos for Heterogeneous Architectures
D. Sahasrabudhe, E. T. Phipps, S. Rajamanickam, M. Berzins.
In Sixth Workshop on Accelerator Programming Using Directives (WACCPD), 2019, DOI: https://doi.org/10.1007/978-3-030-49943-3_7
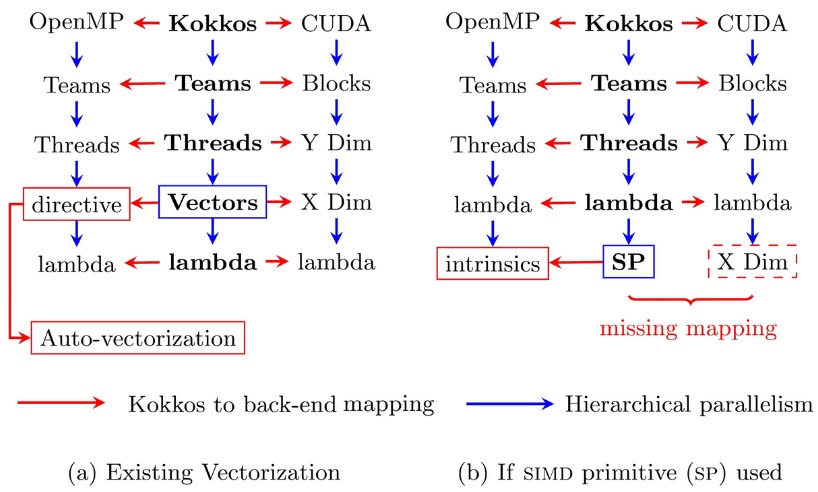
Figure 1: Figure a. shows the mapping of Kokkos' hierarchical parallelism to OpenMP and CUDA without using the SIMD primitive. Figure b. shows the missing CUDA backend for the SIMD primitive, which does not let Kokkos use such primitives for efficient vectorization. This missing piece is added as part of this work.
Abstract
As computer architectures are rapidly evolving (e.g. those designed for exascale), multiple portability frameworks have been developed to avoid new architecture-specific development and tuning. However, portability frameworks depend on compilers for auto-vectorization and may lack support for explicit vectorization on heterogeneous platforms. Alternatively, programmers can use intrinsics-based primitives to achieve more efficient vectorization, but the lack of a GPU back-end for these primitives makes such code non-portable. A unified, portable, Single Instruction Multiple Data (SIMD) primitive proposed in this work, allows intrinsics-based vectorization on CPUs and many-core architectures such as Intel Knights Landing (KNL), and also facilitates Single Instruction Multiple Threads (SIMT) based execution on GPUs. This unified primitive, coupled with the Kokkos portability ecosystem, makes it possible to develop explicitly vectorized code, which is portable across heterogeneous platforms. The new SIMD primitive is used on different architectures to test the performance boost against hard-to-auto-vectorize baseline, to measure the overhead against efficiently vectroized baseline, and to evaluate the new feature called the “logical vector length” (LVL). The SIMD primitive provides portability across CPUs and GPUs without any performance degradation being observed experimentally.
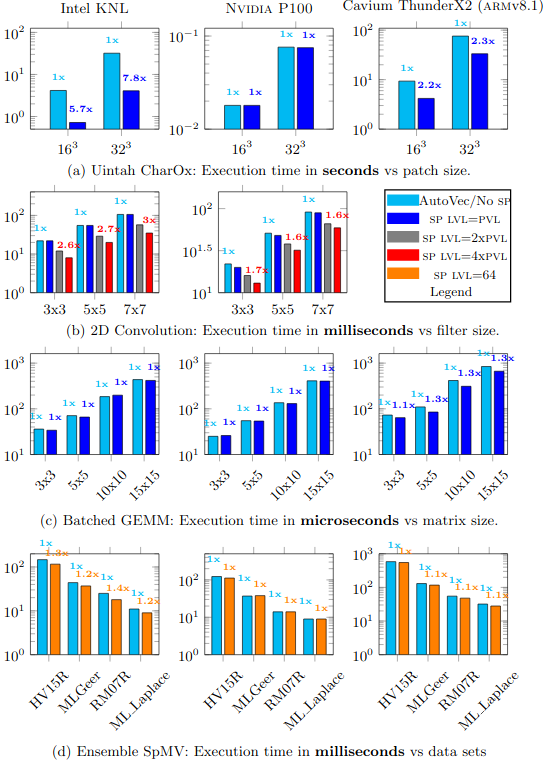
Figure 2: Figure a: The baseline is not auto-vectorized efficiently. Superlinear speedups due to efficient vectorization by the SIMD primitive on Uintah's CharOx kernel. No GPU overhead. Figure b: The baseline is efficiently vectorized. LVL speeds up the 2D convention kernel further on CPUs and GPUs both. Figure c: The baseline GEMM kernel is efficiently vectorized. No overhead on any platform. Figure d: The baseline Ensemble SpMV kernel is efficiently vectorized. The SIMD primitive allows better register usage on CPUs and provides a small boost. No overhead on GPUs.