A Preliminary Port and Evaluation of the Uintah AMT Runtime on Sunway TaihuLight
Z. Yang, D. Sahasrabudhe, A. Humphrey, M. Berzins.
In 9th IEEE International Workshop on Parallel and Distributed Scientific and Engineering Computing (PDSEC 2018), IEEE, May, 2018.
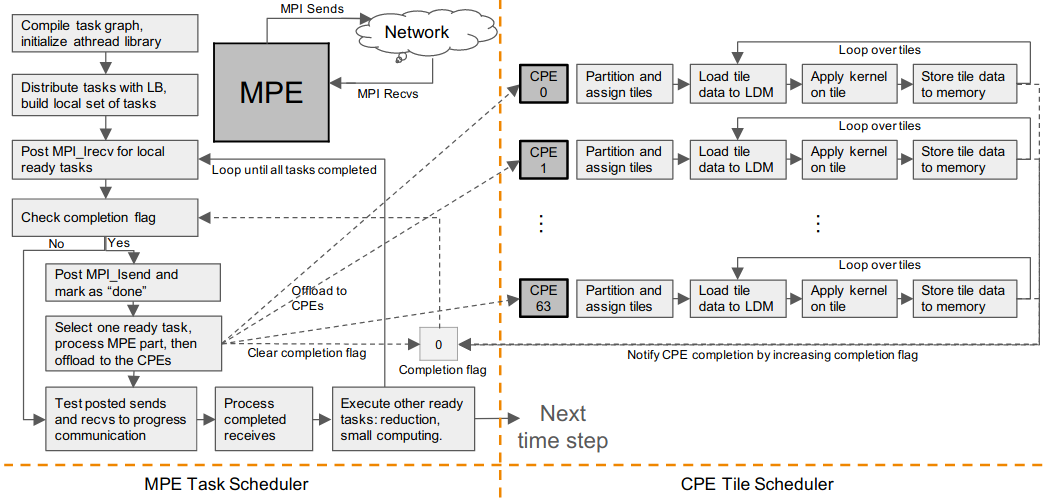
Figure 1: Uintah's asynchronous scheduler for Sunway TaihuLight. The main thread runs on Management Processing Element (MPE) of Sunway's SW26010 processor and asynchronously offloads kernels Computing Processing Elements(CPEs).
Abstract
The Sunway TaihuLight is the world’s fastest supercomputer at present, with a low power consumption per flop and a unique set of architectural features. Applications performance depends heavily on being able to adapt codes to make the best use of these features. Porting large codes to novel architectures such as Sunway is both time-consuming and expensive, as modifications throughout the code may be needed. One alternative to conventional porting is to consider an approach based upon Asynchronous Many Task (AMT) Runtimes such as the Uintah framework considered here. Uintah structures the problem as a series of tasks that are executed by the runtime via a task scheduler. The central challenge in porting a large AMT runtime like Uintah is thus to consider how to devise an appropriate scheduler and how to write tasks to take advantage of a particular architecture. It will be shown how an asynchronous Sunway-specific scheduler, based uponMPI and athreads, may be written and how individual task-code for a typical but model structured-grid fluid-flow problem needs to be refactored. Preliminary experiments show that it is possible to obtain a strong-scaling efficiency ranging from 31.7%to 96.1% for different problem sizes with full optimizations. The asynchronous scheduler developed here improves the overall performance over a synchronous alternative by at most 22.8%, and the fluid-flow simulation reaches 1.17% the theoretical peak of the running nodes. Conclusions are drawn for the porting of full-scale Uintah applications.
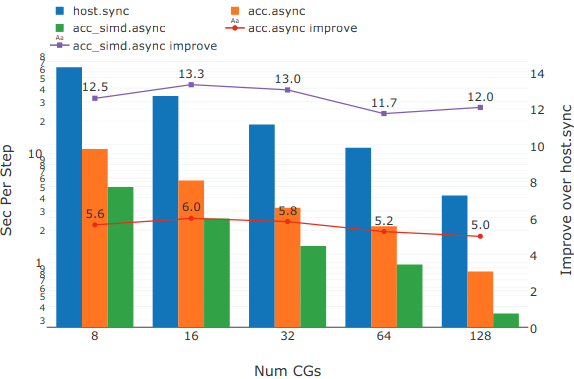
Figure 2: Performance comparison of (i) synchronous host only execution (host.sync), (ii) asynchronous execution with CPE offload (acc.async), and (iii) asynchronous execution with CPE offload and vectorization. Strong scaling across Compute Groups (CGs) is also clearly visible.